Condor-B: BOINC/Condor integration
This document describes the design of Condor-B, extensions to BOINC and Condor so that a BOINC-based volunteer computing project can provide computing resources to a Condor pool.
A central design goal is transparency from the job submitter's viewpoint.
Condor-B must address some basic differences between Condor and BOINC:
- Data model:
- In BOINC, files have both logical and physical names. Physical names are unique within a project, and the file associated with a given physical name is immutable. Files may be used by many jobs. In Condor, a file is associated with a job, and has a single name.
- BOINC is designed for apps for which the number and names of output files is fixed at the time of job submission. Condor doesn't have this restriction.
- Application concept: In Condor, a job is associated with a single executable, and can run only on hosts of the appropriate platform (and possibly other attributes, as specified by the job's ClassAd). In BOINC, there may be many app versions for a single application: e.g. versions for different platforms, GPU types, etc. A job is associated with an application, not an app version.
Assumptions
For simplicity, we'll assume that the BOINC project has been configured to run a certain set of applications for which jobs are commonly submitted to Condor. For each of these applications, admins must
- Create a BOINC application record
- Create input and output templates. Note: in general, the set of input/output files, and their names, must be fixed ahead of time. If an application produces output files with indeterminate names, it must combine these into a zip file (the BOINC wrapper can do this).
- Build the app for one or more platforms (ways of doing this are discussed below).
- Create BOINC "app versions".
Job submission mechanism
We'll use Condor's existing mechanism for sending jobs to non-Condor back ends. This will involve 2 components:
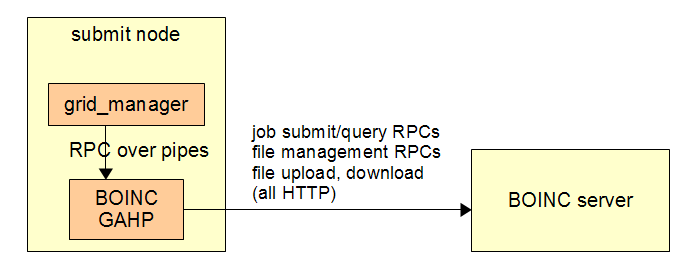
- A "BOINC GAHP" program: runs as a daemon process on the submit node. This handles RPCs (over pipes) from the Condor job router to submit and monitor jobs.
- A new class in Condor's job_router for managing communication with the BOINC GAHP.

The GAHP protocol will be based on the one used for HTCondor's interactions with Globus GRAM. That protocol's description can be found at http://research.cs.wisc.edu/htcondor/gahp/gahp_protocol.txt. From that protocol, we will take the basic syntax and command structure, and these commands:
- ASYNC_MODE_ON
- ASYNC_MODE_OFF
- COMMANDS
- QUIT
- RESULTS
- VERSION
- RESPONSE_PREFIX
To that, we will add the BOINC-specific commands outlined below.
The GAHP protocol is text-based. Each request and reply consists of a single line.
Except for BOINC_SELECT_PROJECT, all the commands are asynchronous: they immediately return S (success) or E (error) depending on whether the request was syntactically valid, and they take a <req id> argument; a RESULTS command fetches the results of completed asynchronous commands.
The commands are:
Specify BOINC project and credentials
BOINC_SELECT_PROJECT project_url authenticator
Result (immediate): NULL or error message
Specify the URL of a BOINC project and the authenticator of an account on that project to which requests will be sent.
Submit a new job batch
BOINC_SUBMIT <req id> <batch name> <app name>
<#jobs>
<job name> <#args> <arg1> <arg2> ...
<#input files>
<src path> <dst filename>
...
...
Result:
NULL (success) or <err msg>
Notes:
- The batch name and job names must be unique over all submissions.
- Each job will have its own set of arguments and input files. But there is a single set of output filenames.
- The input <dst filename>s must agree with the app's template.
- As of now, <dst filename> will always be the filename part of <src path>
- We could add a <dir> argument to prepend to input paths.
Query the status of the jobs of one or more batches
BOINC_QUERY_BATCHES <req id> min_mod_time #batches <batch name1> ... Result: <err msg> | NULL server_time <batch size 1> <job name 1> <status1> ... <batch size 2> ...
Query the jobs in a given set of batches. Only jobs whose DB record has changed (e.g. whose status has changed) since the given min_mod_time are reported (min_mod_time = 0 returns all jobs).
The output includes the current time on the server; you can pass this as min_mod_time in a subsequent call.
The status of each job is either IN_PROGRESS, DONE, or ERROR
Retrieve the outputs of a completed job
BOINC_FETCH_OUTPUT <req id> <job name> <dir> <stderr filename>
<mode: ALL | SOME>
<#file-specs>
<src name> <dst>
...
Result:
error_msg | NULL <exit status> <elapsed time> <CPU time>
Get the results of a completed job, including some or all of its output files. BOINC may replicate jobs to ensure that results are valid. One replica, the "canonical instance", is designated as the authoritative result. If the status is DONE, then the output files of the canonical instance, and its stderr output, are fetched. <exit status> will be zero in this case.
- <dir> is a directory on the local machine where output files are placed by default.
- If mode is ALL, all the job's output files are fetched. File specs are then applied to rename or move output files.
- If mode is SOME, only those output files described by file specs are fetched.
- Each file spec consists of <src name> and <dst>. <src_name> is a filename written by the job.
<dst> specifies where that file should be placed on the local machine.
It may be either:
- An absolute path
- A relative path, in which case <dir> is prepended. Any directories within <dst> must already exist.
If the status is ERROR, the BOINC GAHP looks for an instance for which some information is available (e.g., exit status and stderr output), and returns this information. If there is no such instance, it returns an error message. (A job can fail for various reasons: e.g. all the instances crash, or there is no consensus among the instances, or no instances could be dispatched.)
Abort jobs
BOINC_ABORT_JOBS <req id> <job name> ... Result: NULL|<err msg>
Retire a batch
BOINC_RETIRE_BATCH <req id> <batch name> Result: NULL|<err msg>
The batch's files and database records can be deleted.
Set the "lease time" for a batch
BOINC_SET_LEASE <req id> <batch name> <new lease time> Result: NULL|<err msg>
After this time its files and database records can be deleted.
Results command
RESULTS Result: # of completed commands <req_id1> result1 ...
If any commands have completed, return their results.
Note: the GAHP protocol defines an "async mode" where the GAHP can notify the grid manager that a command has completed by sending "R\n". This is probably not worth doing since polling is very cheap.
Project selection and authentication
For the time being we'll do it this way: Each job submitter has a separate account on the BOINC project (these accounts can be assigned access rights and quotas). The account has a private authenticator (a random string).
The job submitter will create a configuration file containing
- the URL of the BOINC project
- the account authenticator
The BOINC GAHP will read this configuration file at startup, and will handle requests using that account on that project.
Note: we could generalize this a bit by including the project URL and authenticator as an argument to each GAHP request.
Data model
The BOINC GAHP uses BOINC's content-based file management system to manage input files. In this system, files are stored on the BOINC server with names based on their MD5. This provides automatic file immutability It minimizes server disk usage and network transfer in cases where a given file is used by many jobs or batches.
The BOINC database stores records associating files and batches; a file is deleted only when it is no longer associated with any batches.
Implementation notes
The BOINC GAHP handles BOINC_SUBMIT as follows:
- Do an RPC to create a "batch" record
- Make list of all input files; eliminate duplicates
- Compute MD5s of files
- Do an RPC to see which files are already on the BOINC server and create batch/file associations for these files (this avoids a race condition with the file cleanup daemon).
- Do an RPC to copy needed files to BOINC server, and create batch/file associations for these files.
- Do an RPC create jobs
Ways to deploy applications on BOINC
BOINC offers three "environments" in which applications can be deployed:
- Native: This requires making source-code modifications and building the app for different platforms, linking with the BOINC API library.
- BOINC wrapper: Requires apps to be built for different platforms, but no source code mods.
- Virtual machine-based: This would eliminate multi-platform issues but would require volunteer hosts to have VirtualBox installed.
Attachments (1)
- condor.png (11.3 KB) - added by 11 years ago.
{kind=link}
Download all attachments as: .zip